PySpark에서 Polars로의 마이그레이션
데이터 웨어하우스를 운영하면서 매일 수십 개의 Spark 배치 작업을 실행하고 있다. 그런데 작은 규모의 집계 작업에도 소규모 EMR 클러스터를 매번 생성하고 종료하는 과정이 비효율적이라는 생각이 들었다. “분산 처리가 정말 필요한가?”라는 질문에서 시작된 여정이 85%의 성능 향상과 71%의 비용 절감이라는 결과로 이어졌다.
문제: 과한 인프라, 짧은 워크로드
우리의 운영 환경
나는 음악 스트리밍 플랫폼에서 “연령별 차트” 집계 워크플로우를 다음과 같은 환경에서 운영하고 있다:
Amazon EMR 클러스터 구성:
- Primary 1 EA:
m5.xlarge(4 vCPU, 16 GiB) - Core 1 EA:
r5.xlarge(4 vCPU, 32GiB) - Task 노드: 없음
작업 특성:
전체 소요 시간 = 클러스터 생성 시간 + 집계 시간
= 약 6분 + 약 4분
= 약 10분
분산 환경 프레임워크인 Spark를 사용하고 있지만, 실제로는 너무 작은 클러스터였다. Primary 노드 1대, Core 노드 1대로는 Spark의 분산 처리 강점을 제대로 활용할 수 없었다.
왜 단일 머신 쿼리 엔진을 고려했는가?
세 가지 관찰 결과가 있었다.
1. 워크로드가 일정하다
최근 3개월 동안 집계 시간이 4~4.55분 사이에서 안정적으로 완료되었다. 데이터 볼륨에 변동이 없었고, 예측 가능한 리소스 사용 패턴을 보였다.
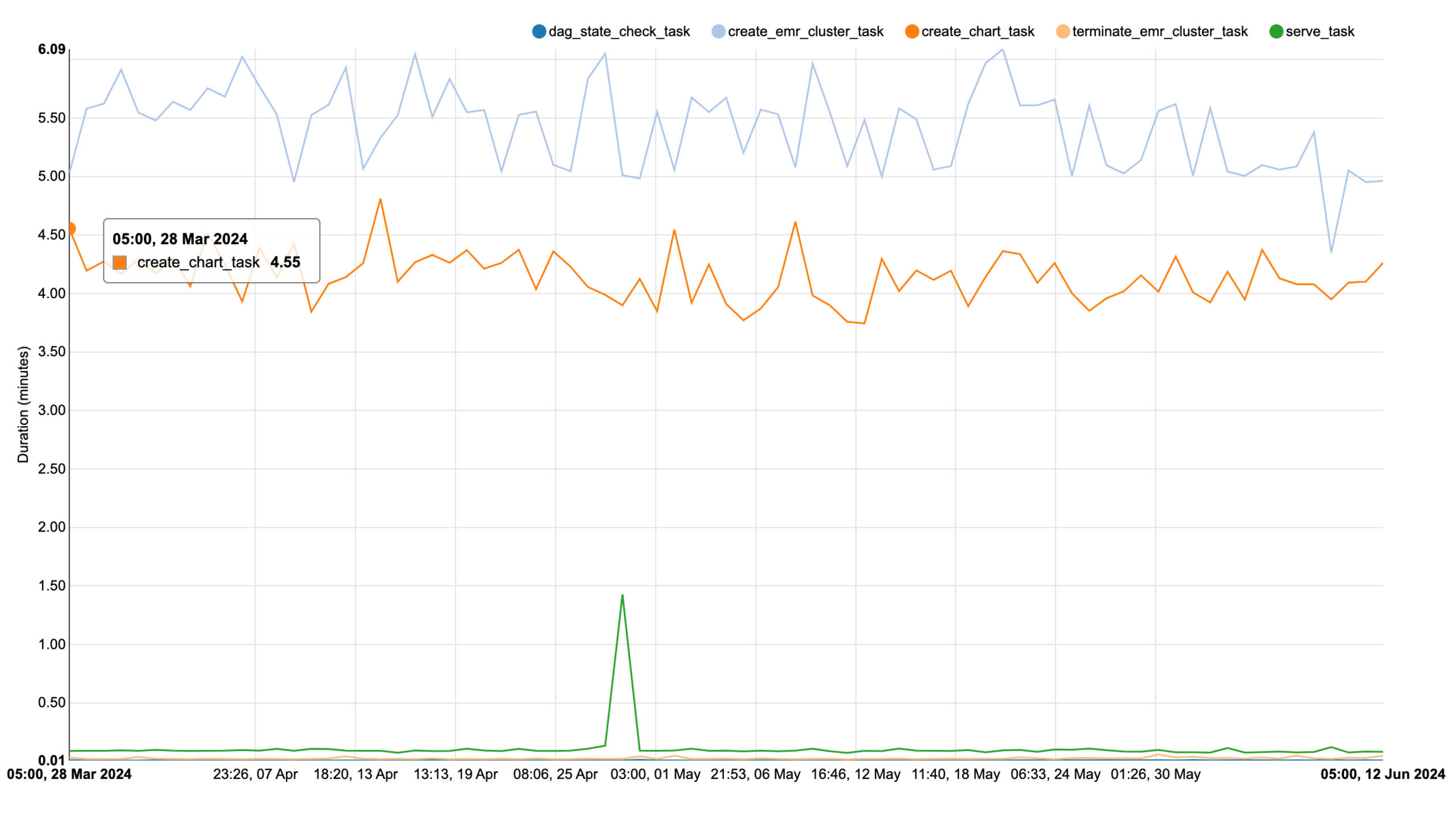
그래프에서 주목할 점은 두 가지다. 하늘색 선(create_emr_cluster_task)은 EMR 클러스터 생성 시간으로 약 5~6분 사이에서 일정하게 유지되고 있다. 주황색 선(create_chart_task)은 실제 차트 집계 작업 시간으로 약 4~4.55분 사이에서 안정적으로 완료되고 있다. 3개월 동안 두 작업 모두 변동이 거의 없다는 것은 워크로드가 예측 가능하고, 데이터 볼륨 증가가 없음을 의미한다.
2. 실제 데이터 용량이 크지 않다
“사용자 재생 로그” 테이블과 “음원 메타데이터” 테이블의 모든 컬럼을 사용하지 않고 각 테이블당 5~6개의 컬럼만 프로젝션했다. 필요한 컬럼만 선택적으로 읽기 때문에 실제 처리 용량은 생각보다 작았다.
3. 불필요한 오버헤드
EMR 클러스터 생성에 6분정도 소요되는데, 실제 작업은 4분만 실행되었다(배보다 배꼽이 더 큰 상황;;). 클러스터 생성 시간이 실제 작업 시간보다 길다는 것은 명백한 비효율이었다.
해결 방안: Polars 선택
Polars vs Apache DataFusion
단일 머신 쿼리 엔진을 검토하면서 두 가지 후보가 있었다:
공통점:
- Apache Arrow 인메모리 컬럼형 포맷 사용
- 단일 머신에서 실행
- SQL 문법 지원
Apache DataFusion:
- Amazon Glue 지원
- ⚠️ ORC 지원 불안정 (Experimental 단계로, 상용 환경에서 쓰기엔 불안..😱)
Polars:
- 성숙한 Python API
- Lazy Evaluation으로 최적화된 실행 계획
- ⚠️ ORC 지원이 불안정 (
scan_pyarrow_dataset()사용 시 느림)
Polars를 선택한 이유는 Python 생태계와의 통합이 뛰어나고, LazyFrame을 통한 최적화된 쿼리 실행 계획 생성 능력 때문이었다.
성능 테스트 설계
다양한 CPU 코어 수와 메모리 조합으로 성능을 측정했다.
테스트 프로세스:
- “음원 메타데이터”와 “사용자 재생 로그” ORC 파일을 클라우드에서 다운로드하면서 동시에 Parquet로 변환 (왜 이렇게 해야 하는지는 뒤에서 설명)
- 변환된 Parquet 파일을 Polars LazyFrame으로 적재
- 집계 쿼리 실행
Parquet 변환 과정은 16 병렬 프로세스로 처리했다.
성능 테스트 결과
CPU 코어 수에 따른 성능
| vCPUs | 메모리 | 음원 메타데이터 Parquet 변환 | 사용자 재생 로그 Parquet 변환 | 집계 (초) |
|---|---|---|---|---|
| 4 코어 | 32GB | 20.38 | 23.09 | 37.52 |
| 16GB | 20.07 | 22.17 | 36.34 | |
| 12GB | 20.6 | 22.3 | 36.12 | |
| 8GB | 18.36 | Out of Memory | - | |
| 8 코어 | 32GB | 17.24 | 20.00 | 30.80 |
| 12GB | 17.75 | 24.04 | 31.36 | |
| 16 코어 | 32GB | 16.22 | 18.46 | 29.77 |
| 12GB | 17.45 | 23.81 | 28.588 |
핵심 인사이트
1. 메모리 영향이 제한적이다
4 코어 기준으로 32GB, 16GB, 12GB 메모리에서 성능 차이가 거의 없었다. 36초 전후로 일정한 성능을 보였다. 이는 워크로드가 메모리 바운드가 아니라 CPU 바운드임을 의미한다.
2. CPU 코어 수가 성능에 미치는 영향
- 4 코어 → 8 코어: 약 17% 향상 (36.12초 → 30.80초)
- 8 코어 → 16 코어: 약 3% 향상 (30.80초 → 29.77초)
8 코어 이상에서는 성능 향상이 미미했다. Parquet 변환을 16 병렬로 처리하기 때문에 8 코어까지만 효과적이었다.
3. 최적 구성
코어 4개, 메모리 12GB가 가장 비용 효율적인 구성이었다. 36.12초의 수행 시간으로 충분히 빠르면서도, 리소스 사용을 최소화할 수 있었다. 클라우드 환경에서는 사용하는 만큼 비용을 지불하기 때문에, 불필요하게 높은 스펙을 사용하는 것은 곧 예산 낭비로 이어진다. 최소 리소스로 목표 성능을 달성하는 것이 핵심이었다.
비용 분석
월간 비용 비교 (1시간 사용 가정)
PySpark (EMR 클러스터):
| 항목 | 비용 (월간) |
|---|---|
| EMR m5.xlarge master node | $1.46 |
| EMR r5.xlarge core node | $1.92 |
| EC2 m5.xlarge (master) | $7.18 |
| EC2 r5.xlarge (core) | $9.25 |
| 합계 | $19.81 |
Polars (단일 EC2):
| 항목 | 비용 (월간) |
|---|---|
| EC2 m6g.xlarge (4 vCPU, 16GiB) | $5.72 |
| 합계 | $5.72 |
비용 절감: PySpark $19.81/월 → Polars $5.72/월 (71.13% ⬇️)
추가 이점
1. Docker 이미지 용량 감소
크기 절감: PySpark 1.97GB → Polars 593MB (69.99% ⬇️)
빌드 시간이 단축되고, 이미지 전송 시간도 줄어들었다.
2. 불필요한 Primary 노드 제거
Spark는 Driver 노드(Primary)와 Executor 노드(Core)를 별도로 운영해야 하지만, Polars는 단일 노드에서 모든 작업을 처리한다.
3. 실제 배포: EKS Pod 기반 운영
Polars 워크플로우는 EKS(Elastic Kubernetes Service) Pod로 구동시켰다. 최적 구성인 4코어 16GB 스펙(m7g.xlarge)을 보장하기 위해 Dedicated K8s Node를 프로비저닝했다.
# Pod 리소스 요청
resources:
requests:
cpu: "4"
memory: "16Gi"
limits:
cpu: "4"
memory: "16Gi"
여기서 중요한 점은 Node Selector와 Taint/Toleration을 사용해 특정 EC2 인스턴스에만 배포되도록 보장한 것이다. 다른 워크로드가 동일 노드에서 실행되면 Polars의 성능이 영향을 받을 수 있기 때문이다.
# Node Selector로 전용 노드 지정
nodeSelector:
workload-type: polars-dedicated
# Toleration으로 전용 노드 접근
tolerations:
- key: "dedicated"
operator: "Equal"
value: "charts-by-age-polars"
effect: "NoSchedule"
이렇게 하면 Fault Tolerance도 확보할 수 있다. K8s가 Pod 장애를 감지하면 자동으로 재시작하고, 노드 장애 시에도 다른 Dedicated 노드로 재스케줄링된다.
성과
수행 시간 단축
PySpark:
전체 소요 시간 = 클러스터 생성 + 집계 시간
= 약 6분 + 약 4분 5초
= 약 10분
Polars:
전체 소요 시간 = 프로비저닝 + 집계 시간
= 거의 즉시 (컨테이너 기반) + 약 36초
≈ 약 1분
시간 단축: PySpark 10분 → Polars 1분 (90% ⬇️)
핵심 지표
- 수행 시간 감소: 85.42% (집계 시간만 비교)
- 하드웨어 스펙 축소: 코어 4 + 코어 4 → 코어 4 단일 노드
- 메모리 최적화: 32GB → 12GB
- 비용 절감: 71.13%
- Docker 이미지 용량 감소: 69.99%
문제점과 해결
ORC 파일 지원 불안정
Polars는 ORC 파일을 지원하지만 불안정하다. scan_orc() API조차 제공하지 않고, scan_pyarrow_dataset()을 사용해야 하는데 이는 Parquet보다 상당히 느렸다.
해결책:
ORC 파일을 클라우드에서 다운로드하면서 동시에 Parquet로 변환하는 파이프라인을 구축했다. 이렇게 하면:
- 로컬에서 열 기반(columnar) 인메모리 포맷(Arrow)으로 즉시 처리
- Polars의 빠른 Parquet 읽기 성능 활용
- LazyFrame을 통한 최적화된 쿼리 실행 계획 생성
향후 과제
1. ORC → Parquet 전환
데이터 소스를 ORC에서 Parquet로 전환하면 Polars뿐만 아니라 Spark의 성능도 향상된다. Parquet는 읽기 중심 워크로드에 최적화되어 있고, Apache Spark와의 호환성이 뛰어나다.
Parquet vs ORC:
- Parquet: 읽기 중심 워크로드에 최적화, Spark와 완벽한 호환
- ORC: 쓰기 중심 작업에 적합, Hive ACID 트랜잭션 지원
우리 워크로드는 읽기 중심이므로 Parquet가 더 적합하다.
2. SQL 기반 Syntax-Agnostic 환경
현재는 Polars 문법과 PySpark 문법이 달라서 코드 이관 시 수정이 필요하다. 집계 작업을 API 형태가 아닌 SQL로 작성하면 쿼리 엔진 프레임워크의 문법에서 자유로워질 수 있다.
장점:
- PySpark ↔ Polars 간 전환이 용이
- SQL만 이관하면 되므로 유지보수 간소화
단점:
- 긴 SQL은 유지보수가 어려울 수 있음
- IDE의 코드 자동완성 지원이 제한적
결론
“모든 데이터 작업에 분산 처리가 필요한가?”라는 질문에서 시작된 이 프로젝트는 명확한 답을 제시했다. 작은 규모의 워크로드에는 단일 노드 엔진이 더 효율적이다.
핵심 교훈
이번 마이그레이션을 통해 가장 크게 깨달은 것은 적절한 도구 선택의 중요성이었다. Spark는 강력한 분산 처리 프레임워크지만, 소규모 데이터와 단순한 집계 작업에는 과한 도구였다. Polars와 같은 단일 노드 엔진이 훨씬 효율적이었다.
성공적인 전환을 위해서는 워크로드의 특성을 정확히 이해하는 것이 필수적이었다. 우리 워크로드는 예측 가능한 데이터 볼륨, 짧은 실행 시간, 그리고 메모리가 아닌 CPU 바운드 특성을 가지고 있었다. 이런 특성을 이해하고 있었기 때문에 단일 노드 엔진 전환이 가능했다.
또한 추측이 아닌 데이터를 기반으로 의사결정을 내렸다는 점도 중요했다. 다양한 CPU와 메모리 조합으로 실험하여 최적의 구성(4 코어, 12GB)을 찾았고, 이를 통해 85%의 성능 향상과 71%의 비용 절감을 동시에 달성할 수 있었다. 성능과 비용은 트레이드오프가 아니라 함께 개선할 수 있다는 것을 증명했다.
적용 가능한 시나리오
다음과 같은 경우에 단일 노드 엔진 전환을 고려할 수 있다:
- 소규모 EMR 클러스터 (2-3 노드)로 운영 중인 워크로드
- 데이터 볼륨이 일정하고 예측 가능한 작업
- 짧은 실행 시간 (10분 이하)의 집계 작업
- 컬럼 단위 프로젝션으로 실제 데이터 용량이 작은 경우
이제 적절한 도구를 선택하는 것이 얼마나 중요한지 실감한다. Polars는 우리 워크로드에 완벽하게 맞는 도구였고, 성능과 비용을 동시에 최적화할 수 있었다.