Trino 느린 쿼리 분석과 성능 최적화
Trino 클러스터를 운영하다 보면 예상보다 느린 쿼리들을 마주하게 된다. 단순히 “쿼리가 느리다”는 것만으로는 문제를 해결할 수 없다. 정확한 원인을 파악하고 체계적으로 접근해야 한다.
이 글에서는 실제 운영 환경에서 발생한 Trino 느린 쿼리 문제를 해결한 과정을 다룬다. JVM 프로파일링을 통한 정확한 병목 지점 파악부터 메타스토어 최적화까지, 42초에서 3초로 성능을 개선한 실전 경험을 공유한다.
문제
사내 Trino 사용자들이 서버 로그 조회 쿼리가 많이 느리다는 보고를 받았다. 아래의 쿼리처럼 특별히 복잡한 쿼리가 아니어도, 수행시간이 무려 40초를 넘겨버렸다.

우리 팀은 Amazon EMR에서 Trino를 운영하고 있었고, 메타스토어로는 Amazon Glue Data Catalog를 사용하고 있었다. 클러스터 사양도 64 CPU Cores에 512GB Memory로 충분히 여유로웠다. 문제가 된 테이블은 서버 로그 테이블로, 1시간마다 파티션을 생성하는 시간 기반 파티션 테이블이었다.
그런데 Trino 클러스터가 널널한 시간대에 내가 동일한 쿼리를 수행해도 역시나 30초를 훨씬 넘겨버렸다. 클러스터 사양이 굉장히 높음에도 불구하고 이런 성능 저하가 발생한 것은 명백히 비정상적인 상황이었다.
분석
처음에는 당연히 EXPLAIN ANALYZE로 쿼리 실행 계획을 확인해봤다. 그런데 결과를 보니 플래닝에서 많은 시간을 소요하고 있었다.

하지만 쿼리 계획 시간을 알수는 있지만, 정확히 어디서 느린지는 알수가 없었다. 플래닝 단계에서 상당한 시간이 소요되고 있다는 것은 확인할 수 있었지만, 구체적으로 어떤 부분에서 병목이 발생하고 있는지 파악하기 어려웠다. 쿼리 실행 계획 자체는 정상적으로 생성되었고, 플래닝 시간이 전체 실행 시간의 대부분을 차지하고 있었다. 단순한 SELECT 쿼리임에도 불구하고 40초 이상 소요되는 상황에서 더 깊이 있는 성능 분석 도구가 필요하다는 것을 깨달았다.
그래서 JVM 프로파일링을 통해 정확한 병목 지점을 파악해보기로 했다.
프로파일링을 실행한 후, 프로파일 뷰로 Trino의 쓰레드들이 얼마나 CPU 시간을 소요하는지 확인해보았다.
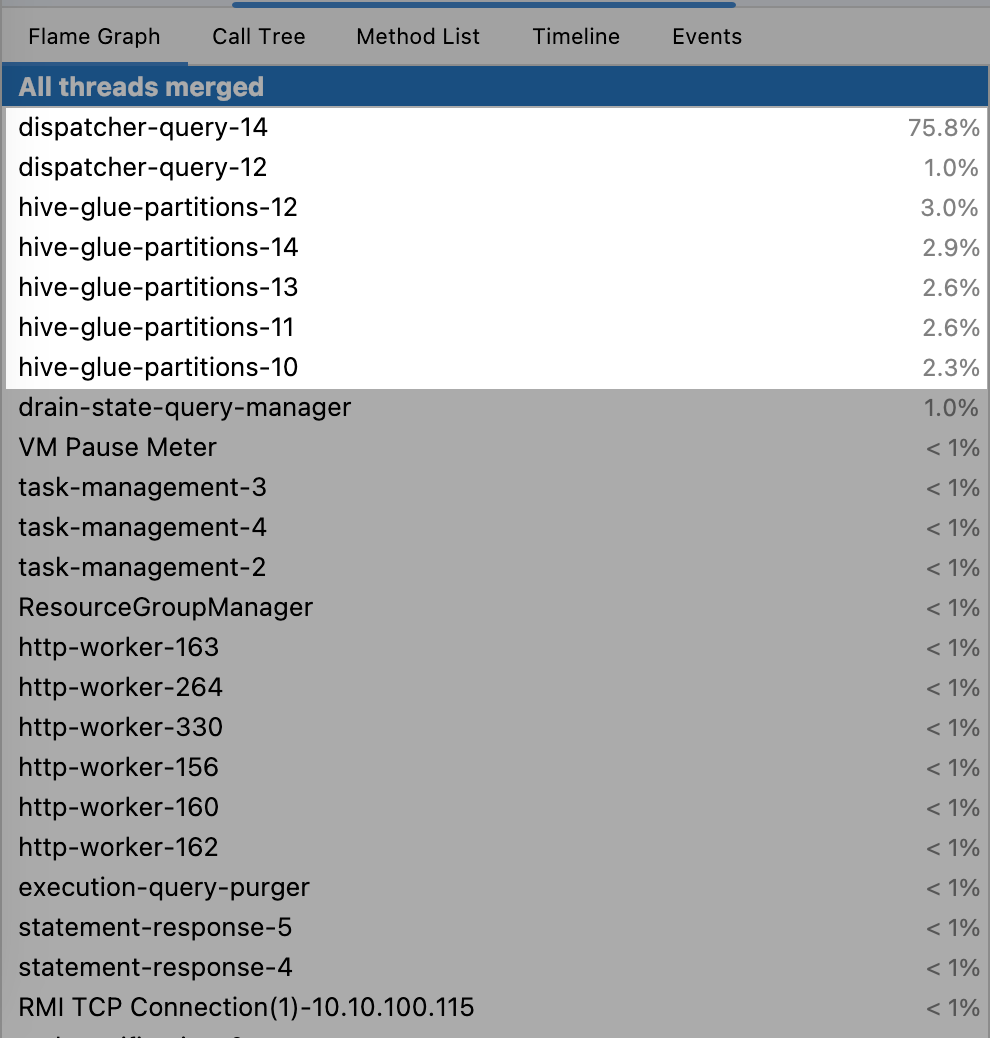
결과를 보니 놀라운 발견이 있었다. 가장 눈에 띄는 부분은 dispatcher-query-14와 dispatcher-query-12가 각각 75.8%와 1.0%의 CPU 시간을 차지하고 있다는 점이었다. 이는 쿼리 디스패처가 전체 실행 시간의 대부분을 담당하고 있음을 의미했다.
그리고 hive-glue-partitions 관련 작업들이 여러 스레드에서 실행되고 있었다. 각각 2% - 3.0%의 CPU 시간을 사용하고 있었고, Hive 메타스토어에서 파티션 정보를 가져오는 과정에서 상당한 오버헤드가 발생하고 있음을 시사했다.
이제 EXPLAIN ANALYZE로는 파악할 수 없었던 정확한 병목 지점을 식별할 수 있었다. 스레드별 CPU 사용량 분석으로 문제 영역이 명확해졌고, 메타스토어 관련 작업의 성능 영향도를 정량적으로 측정할 수 있게 되었다.
더 자세한 분석을 위해 Flame Graph를 확인해보았다.

Flame Graph를 자세히 분석해보니, 두 가지 중요한 Flame이 눈에 띄었다.
1. io.trino.sql.planner.LogicalPlanner.runOptimizer
- 역할: 쿼리 최적화 규칙들을 실행하는 핵심 함수
- FlameGraph에서의 의미: logical 플랜에 상당한 시간을 소요
- 분석: 쿼리 최적화 과정에서 예상보다 많은 시간이 소요되고 있음
2. io.trino.plugin.hive.HivePartitionManager.tryLoadPartitions
- 역할: Hive 메타스토어에서 파티션을 조회하는 함수
- FlameGraph에서의 의미: Hive 메타스토어에서 파티션 로딩에 시간을 소요
- 분석: 메타스토어에서 파티션 정보를 가져오는 과정이 주요 병목 지점
이 분석을 통해 몇 가지 핵심 인사이트를 얻을 수 있었다. 쿼리 실행 자체보다 메타데이터 조회 과정에서 병목이 발생하고 있었고, 파티션 정보 로딩이 전체 성능에 미치는 영향이 예상보다 컸다. 단순한 SELECT 쿼리임에도 불구하고 복잡한 최적화 과정이 필요하다는 것을 깨달았다.
근본 원인 분석
이제 문제의 근본 원인이 명확해졌다. 결론은 Trino 코디네이터에서 쿼리의 logical 실행 계획을 생성할때, 파티션 정보 조회에 많은 시간을 소비하고 있었던 것이다.
Trino는 메타스토어를 Amazon Glue Data Catalog를 사용하는데, 이는 REST로 모든 메타스토어의 연산을 처리한다는 뜻이다. REST는 비싸고 느린 연산이기 때문에, 최대한 안쓰거나 덜써야 퍼포먼스가 향상된다.
또 하나의 문제는 서버 로그 테이블이 1시간마다 파티션을 생성하고, 메타스토어에 1년치의 너무 많은 파티션 정보가 저장되어있었다는 점이었다. 계산해보니 1시간 × 24시간 × 365일 = 8,760개의 파티션이 있었다. 각 파티션마다 개별 API 호출이 발생하고, REST API 기반의 직렬화/역직렬화 비용으로 인한 네트워크 레이턴시가 누적되어 상당한 성능 저하를 야기하고 있었다.
해결
이제 해결 방안을 고민해봤다. 이 문제의 해결은 3가지 방법을 고려할 수 있었다.
1. hive-glue-partitions 워커 스레드 확장
- 장점: 즉시 적용 가능
- 단점: 클러스터 리소스 사용량 증가, 근본적 해결책 아님
2. 불필요한 파티션을 Glue Catalog에서 삭제
- 장점: 메타스토어 부하 직접 감소
- 단점: 데이터 소스는 남겨둬야 함 (메타데이터만 삭제)
3. 캐시 설정
hive.metastore-cache.cache-partitions: 기본값truehive.metastore-cache-ttl: 캐시 유효 시간 설정
하지만 리소스를 확장하는 것은 클러스터 성능에 조금이라도 영향을 줄 수 있어서, 사용자의 파티션 쿼리 시나리오를 분석해서 3개월치만 파티션 윈도우를 유지하여 해결했다.
이렇게 하면 파티션 수가 8,760개에서 2,160개로 75% 감소하게 되고, 메타데이터 조회 시간이 단축되어 API 호출 횟수가 대폭 감소했다. 실제 데이터는 보존하면서 메타데이터만 정리하여 사용자 영향도 최소화할 수 있었다.
성과

문제의 쿼리를 다시 수행한 결과는 놀라웠다. 약 42초에서 약 3초로, 약 90%나 감소했다. 실질적으로 불가능했던 로그 조회가 즉시 가능해졌고, 클러스터 리소스 사용량도 최적화되었다.
응답 시간이 93% 단축되었고, 파티션 수도 75% 감소했다. 메타스토어 API 호출이 대폭 감소하여 네트워크 오버헤드가 최소화되었다. 데이터 분석 및 디버깅 작업 효율성이 대폭 향상되었고, 전체적인 데이터 팀의 업무 생산성이 증대되었다. 사용자 만족도와 시스템 신뢰성도 향상되었다.
눈에 띄는 응답 시간을 받을 수 있었다.
결론
이번 Trino 느린 쿼리 문제 해결 경험을 통해 몇 가지 중요한 교훈을 얻을 수 있었다.
EXPLAIN ANALYZE만으로는 복잡한 성능 문제의 근본 원인을 파악하기 어려웠고, JVM 프로파일링과 Flame Graph 분석을 통해 정확한 병목 지점을 식별할 수 있었다. 쿼리 실행 자체보다 메타데이터 조회 과정에서 발생하는 오버헤드가 성능에 미치는 영향이 예상보다 컸으며, 특히 시간 기반 파티션 테이블의 경우 파티션 수 관리가 성능에 직접적인 영향을 미친다는 것을 깨달았다.
42초에서 3초로 약 90% 성능을 개선한 결과, 단순한 쿼리 최적화를 넘어서는 메타데이터 관리의 중요성과 프로파일링 도구를 활용한 정확한 병목 지점 파악의 필요성을 확인할 수 있었다. 운영 환경에서는 체계적인 접근과 예방적 관리가 필수임을 다시 한번 느꼈다.